
05 | Seeing the Signal: The Detection Domains of Clinical Algorithmic Safety
Series 1 | Issue 05

The Detection Layer
Domain 1 defines exposure. Domain 2 makes it traceable. Domain 3 determines if it’s performing as expected.
Remove any one, and clinical AI surveillance fails. This issue introduces the detection layer.
Issues 03 and 04 made an argument that this series will not retreat from.

Three feedback loops operate in every deployed clinical AI system. They generate automation bias, reshape clinical reasoning, and contaminate the training data used to retrain the next version of the model.
They do not merely produce harm; they obscure it.
However, the infrastructure most health systems currently rely on—dashboards, aggregate performance metrics, and vendor reports—was never designed to see any of it.
Issue 04 named the gap precisely:
Detecting the three feedback loops requires five signal types. Each appears at a different point after deployment, requires different data infrastructure, and needs a designated owner to act on it when it arrives.
This is not a gap in aspiration. It is a gap in infrastructure.
Issue 05 begins to close it.
The Detection Layer
The Epidemiology of Algorithms organizes post-deployment surveillance into six domains.
In this issue, we examine the first three:
Domain 1 — Algorithm Exposure Science
Domain 2 — CAIT (Clinical Algorithm Identification and Traceability)
Domain 3 — Algorithmovigilance
Together, they form the Detection Layer.
D1, D2, and D3 are not three parallel tools. They are a dependency structure.
D1 defines what is being surveilled
D2 makes it traceable
D3 detects whether it is performing as expected
Remove any one, and the surveillance system cannot function.
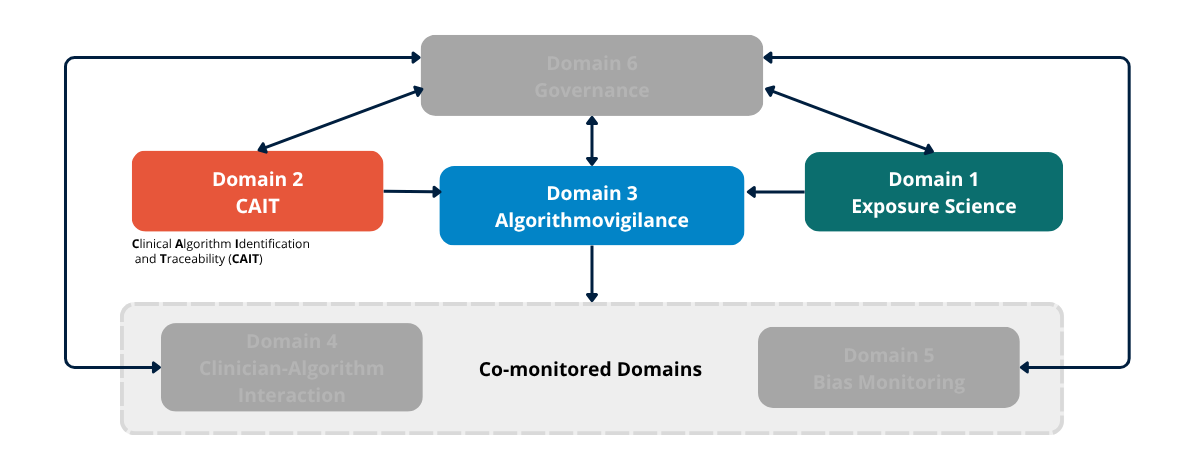
Figure 3a. The Six-Domain Surveillance Architecture. Detection Layer. Domains 1 (Algorithm Exposure Science), 2 (CAIT), and 3 (Algorithmovigilance) are introduced in full color as the detection layer. Domains 4, 5, and 6 remain greyed out pending their introduction in Issues 05–07.
Domain 1 — Algorithm Exposure Science
Algorithm Exposure Science characterizes how algorithms interact with clinical workflows.
It is the surveillance prerequisite—the domain that defines the exposure before any other domain can operate.
The logic comes directly from epidemiology’s exposure science tradition. Before attributing harm to a workplace hazard, occupational epidemiology requires quantified exposure assessment.
Clinical algorithmic safety requires the same discipline.
An algorithm that fires rarely in low-acuity settings and has low clinician acceptance does not create the same exposure profile as one embedded in a critical care pathway, which fires on every patient and has recommendations accepted without review 73% of the time.
Treating those exposures as equivalent is an exposure misclassification error.
The Four Exposure Dimensions
Algorithm exposure has four measurable dimensions that D1 must characterize:
Exposure frequency How often the algorithm fires per patient, per shift, per unit. Frequency determines the scale at which behavioral effects accumulate.
Embedding depth Where the output appears in the clinical workflow. Algorithms presented before the clinician forms an independent judgment carry a higher risk of automation bias than those presented afterward.
Automation bias propensity How often clinicians accept recommendations without independent verification. This is a population-level behavioral measurement that changes over time, across alert types, and across exposure quartiles.
It is the earliest detectable signal of activation of the Override/Adaptation Loop.
Workflow dynamics How the algorithm has changed the clinical workflow since deployment. When teams reorganize their processes around an algorithm’s outputs, the algorithm has become embedded in a way that frequency counts alone cannot capture.
The Algorithm Journey Map
The algorithm journey map provides a structured method for tracing the full pathway by which a clinical AI model reaches patients—from the training environment through deployment integration, clinical workflow positioning, clinician interaction, and patient outcomes.
It identifies exposure-modifying factors at each transition.
This is D1 operationalized.
Surveillance Beyond Deployment
While the FDA mandates oversight at the pre-deployment stage for AI-enabled devices, this framework requires continuous monitoring throughout deployment.
The question is not only how the algorithm is intended to be used.
It is how it is actually being used—by which clinicians, under what conditions, with what behavioral patterns—six months after the implementation team has moved on.
The Real-World Performance Gap as an Exposure Science Problem
A consistent finding in the clinical AI implementation literature is the gap between controlled validation performance and real-world deployment performance.
This is routinely attributed to distribution shift.
That explanation is incomplete.
Two distinct mechanisms are operating simultaneously, and D1 is what distinguishes them:
Context shift: the deployment population differs from the training population
Use shift: the algorithm is being used differently than it was tested
Introduced at a different point in the workflow. Accepted at a different rate. Embedded in a clinical environment that validation never measured.
Context shift requires data-driven surveillance instruments. Use shift requires workflow-driven ones.
Without D1, both look the same—and the response to each is different.
Without D1, degraded performance due to context shift, use shift, and feedback-loop contamination are indistinguishable.
Exposure science is what separates them.
The Core Question of D1
How many patients does this algorithm touch, and how is it changing clinician behavior over time?
Domain 2 — CAIT (Clinical Algorithm Identification and Traceability)
CAIT provides a unique, version-controlled identifier for every deployed clinical algorithm.
It is the condition of possibility for surveillance.
Without it, algorithms cannot be traced across deployments. Adverse events cannot be linked to specific versions. A model update cannot be distinguished from a stable deployment.
Multi-site signal aggregation—the mechanism by which rare but serious harms become detectable—is impossible.
The Analogy Is Precise
CAIT is to clinical AI what the National Drug Code is to pharmaceuticals, and what the Unique Device Identifier is to medical devices.
Both systems exist for the same reason:
Population-level safety monitoring requires a shared, standardized identifier that links every instance of use to a traceable record of what was used, when, which version, and the clinical context.
Clinical AI has no such system.
That is not a regulatory oversight. It is a structural gap.
What Currently Exists, and Why It Is Insufficient
As of 2025, more than 1,250 AI-enabled medical devices have received FDA authorization.
But the current registry is not a surveillance system. It is an authorization list, that is insufficient for three reasons:
1. It is incomplete - It covers only FDA-authorized devices. Most deployed clinical AI-EHR-integrated models, decision-support tools, and risk-stratification systems are not included.
They are invisible.
2. It lacks version control - Retrained or updated models are not distinguishable from their original versions. Version-specific performance data does not exist.
3. It has no point-of-care traceability - When something goes wrong, there is no mechanism to link that event to the exact algorithm version that was in use at that moment.
That linkage is the foundation of surveillance, and it is missing.
CAIT in Practice
The AIPassport framework demonstrates that large-scale algorithm traceability is technically achievable:
Verifiable digital identities
Full version control
Data lineage tracking
Regulatory documentation
The barrier is not feasibility — It is whether institutions and regulators require it.
The Scan-to-Report Function
At the point of care, CAIT operates via a scan-to-report mechanism.
When a clinician encounters unexpected or discordant algorithm behavior, they scan a QR code linked to the algorithm’s CAIT identifier and submit a structured report tied to:
The algorithm version
The clinical context
The specific encounter
This closes a critical gap.
Current reporting systems are retrospective, voluntary, and not version-linked.
CAIT makes reporting prospective, embedded, and traceable.
CAIT does not detect harm. It makes detection possible. Without CAIT, surveillance has no address.
Domain 3 — Algorithmovigilance
Algorithmovigilance is the active surveillance engine of the detection layer.
It applies pharmacovigilance-derived methods to a question that cannot be answered at the bedside:
Is this algorithm performing as expected across the population—and is that performance changing over time?
Lessons from Pharmacovigilance
Five principles translate directly:
Post-approval evaluation
Case reporting
Data standardization
Causality assessment
Adverse event dissemination
Clinical AI currently lacks most of this infrastructure.
What Current Monitoring Misses
Most AI monitoring today is limited to statistical drift detection:
Covariate shift
Concept shift
These detect changes in data distributions.
They do not detect:
Automation bias accumulation
Changes in clinician behavior
Feedback loop activation
They are exogenous drift monitors deployed in systems generating endogenous drift.
Algorithmovigilance is the mechanism for closing that gap.
The Core Question of D3
Is this algorithm performing as expected across the population— and is that performance changing over time?
What Comes Next
The detection layer can see the signal, but sight without action is inadequate.
D1, D2, and D3 make signals visible, but visibility alone, without acknowledgment, is not a surveillance system.
It is a warning without a response.
Issue 06 will introduce the Response and Accountability Layer.
Two Questions
The detection layer answers the question: Can we see it?
The response layer answers the question: What do we do when we see it?
Between those two questions lies the difference between a surveillance system and a safety system.
“Trust in algorithmic systems should be continuously earned through rigorous, population-level surveillance rather than historically inherited from initial validation or deployment approval.” - Anne E. Burnley, MD