
Issue 02 - Clinical AI as a Population-Level Intervention: The Algorithm Exposure Model
Anne E. Burnley, MD, MHS, MS | The Epidemiology of Algorithms | Issue 02

“Six Blind Men and an Elephant” is an ancient Indian fable, documented in the Tittha Sutta around 500 BC.
Six blind men encounter an elephant.
Each touches a different part and declares a different truth: A tree, a fan, a wall, a snake, a rope, a spear.
Each is absolutely certain. None is wholly wrong. But none can see the whole.

I thought about that fable one afternoon in our occupational health clinic.
I was reviewing audiograms for a workforce I had been watching for years. Halfway through that stack, I noticed something that shouldn’t have been there.
One third of the group had significant threshold shifts. Not one worker. Not a cluster. A third — distributed quietly across a population I happened to be watching in its entirety. No one had complained. The shift had aggregated in silence.
A worksite visit confirmed what I suspected. We contained the harm because we caught it early. Without that intervention, those workers would have presented years later with permanent hearing loss, entirely preventable.
What it required: One provider. One population. Complete visibility.
Remove any one of those three conditions, and the shift continues. Distribute that workforce across three clinics, assign them to five different providers, and the signal disappears into the noise of individual encounters. Each provider sees their fraction. Nobody sees the elephant.
“Clinical AI does not act on one patient. It acts on every patient to produce population-level effects.” — Anne E. Burnley, MD
Clinical AI is deployed across thousands of providers and hundreds of institutions. Every clinician sees their piece, their patient, their alert, their encounter. Nobody is standing back, watching the whole animal.
That is the problem this discipline exists to solve.
THE PROBLEM
When the Epic Sepsis Model was deployed at hundreds of hospitals beginning in 2018, no systematic surveillance infrastructure existed to monitor its performance. The model was proprietary. External validation was not required before deployment.
It took a research team at Michigan Medicine, working retrospectively, on their own data, with limited vendor cooperation, to find out what the model was actually doing. What they found: the algorithm missed two-thirds of sepsis patients while firing alerts on nearly one in five hospitalizations. Epic had reported performance that would correctly distinguish sepsis patients from non-sepsis patients roughly 8 times out of 10. The real number was barely better than flipping a coin.
The model ran unwatched.
Not because clinicians were careless. But because no architecture existed for watching. No surveillance infrastructure. No signal detection system. No adverse event taxonomy. No unique identifier to track the model across sites or versions.
That is not a technology problem. That is an epidemiological problem that has a solution.
THE ALGORITHM EXPOSURE MODEL
The framework begins with a reframe.
Clinical AI is not a software tool deployed in individual clinical encounters. It is a population-level intervention — operating simultaneously across thousands of providers and hundreds of institutions, producing effects that aggregate into outcomes no single clinician can see.
The Algorithm Exposure Model extends the classical epidemiological triad — agent, host, environment — to clinical AI.
The algorithm is the agent. Its outputs influence the clinician, the decision host, whose clinical decisions then affect the patient. Individual outcomes aggregate into population-level effects. The clinical environment modifies every step: staffing ratios, alert burden, workflow design, and institutional culture around AI trust.
The same algorithm, deployed in different environments, produces different outcomes. Not because the model changes. Because the environment changes its effect.
Algorithms are not inherently biased. But the data they are trained on may carry biases, and algorithms can amplify those biases across populations.
The Algorithm Exposure Model traces a causal pathway from algorithm to patient, six nodes, one chain, one environment that modifies everything. The algorithm generates an output. A clinician interprets it. A clinical decision follows. A patient is affected. Individual outcomes aggregate into population-level effects that no single provider can see at the bedside.
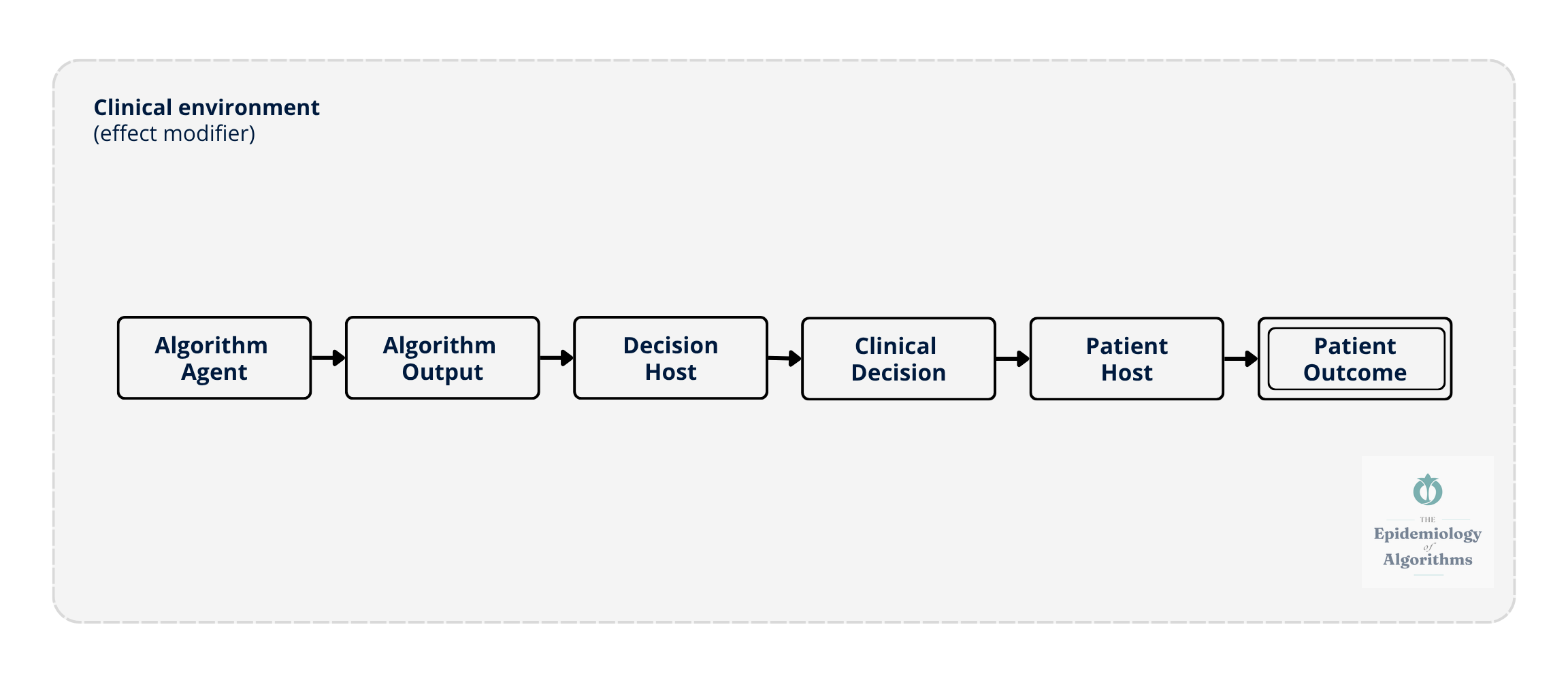
Figure 1. The Algorithm Exposure Model: Linear Causal Chain. The algorithm acts as the agent, generating outputs that influence the decision host (clinician), whose clinical decisions affect the patient host. The clinical environment: Staffing, alert burden, workflow, and institutional culture- acts as an effect modifier at every node. Individual patient outcomes aggregate across settings to produce population-level signals.
WHY CLINICIANS MUST LEAD
The clinician who sees the patient is the only person who can recognize when an algorithm’s recommendation doesn’t fit the clinical picture. The clinician who reviews a hundred alerts in a shift is the only person who can report when the signal-to-noise ratio has become unworkable. The clinician who knows their patient population is the only person who can notice when a subgroup is being systematically missed.
If clinicians do not take a prominent role in AI surveillance and governance, we will have ceded the system’s most important feedback loop.
Our patients will pay the price.
AN OPEN INVITATION
This framework is my best current thinking. It is not finished.
A surveillance architecture for clinical AI, one that actually works at scale, cannot be designed by one physician working alone.
It needs the cardiologist who has watched a risk algorithm miss her patients. The informaticist who knows where the data lives. The patient safety officer has been trying to report an algorithm-associated event, but has nowhere to send it. The health equity researcher who knows which populations are being missed. The nurse who has watched alert fatigue erode her colleagues’ responsiveness.
Post-deployment surveillance of clinical AI is not optional. It is a requirement.
But Figure 1 is not the whole picture. It shows how algorithm-associated events travel. It does not show how they compound.
In Issue 03 - The System Talks Back: Feedback Loops and the Epistemology of Drift, the model becomes dynamic with feedback loops, propagation, and aggregation. The linear model in Figure 1 becomes a living system, changing everything we think about drift.
The chain you saw here talks back. The next issue shows you how.
“Trust in algorithmic systems should be continuously earned through rigorous, population-level surveillance rather than historically inherited from initial validation or deployment approval.” — Anne E. Burnley, MD
In healthcare, particularly, trust must be:
• Measured through subgroup performance
• Maintained through transparent evaluation
• Monitored as models drift
• Re-earned every time a system is updated, retrained, or deployed in a new context
This is what The Epidemiology of Algorithms exists to build.
Next issue, April 16, 2026: The System Talks Back: Feedback Loops and the Epistemology of Drift
The Epidemiology of Algorithms
Anne E. Burnley, MD, MHS, MS
newsletter.epidemiologyofalgorithms.org
Thanks for reading The Epidemiology of Algorithms!
Subscribe to receive new posts and support my work.