
04 | The Infrastructure Gap: Why Surveillance, Detection, and Mitigation Require More Than Just a Dashboard
Series 1 | Issue 04 | The Epidemiology of Algorithms

Issue 03 identified the problem.
Three feedback loops — the Override/Adaptation Loop, the Clinician Learning Loop, and the Training Feedback Loop — can turn a deployed clinical AI system into a dynamic system. Once in use, the system begins to react to its environment, influencing clinician behavior and, in some cases, even creating the very drift it was meant to prevent.
These loops do more than create risk. They make that risk harder to see. Traditional incident review is not built to detect them. Individual clinicians cannot spot them from the bedside. They only become visible when you look across larger populations and over longer periods of time.
Issue 04 asks the next logical question.
If these loops cannot be avoided and routine monitoring cannot consistently detect them, what does an institution actually need to build?
The Governance Reality
This is not a pessimistic conclusion; it is a structural one.
Clinical AI systems are static tools placed into environments that are constantly changing. From the moment they are deployed, their outputs begin interacting with clinicians, workflows, incentives, and data systems that are also evolving. Some of that change comes from outside the model — shifting patient populations, updated protocols, or new disease patterns. Some of it comes from the model itself through the three feedback loops described in Issue 03.
Either way, the result is the same. The gap between the model’s training environment and the real clinical setting widens at deployment. That divergence is not a flaw. It is the predictable outcome of placing a fixed artifact inside a dynamic environment.
That is why initial validation cannot be the endpoint. Responsible AI deployment requires continuous surveillance, not as an optional quality-improvement activity but as a core operational function.
What a Minimum Viable Surveillance Dataset Really Needs
The literature is now clear enough to show what separates a truly useful surveillance dataset from the dashboards most health systems currently rely on. Three components are critical, and all remain largely missing from standard practice.
The first is data provenance markers: clear indicators of whether the training data have outcomes influenced by earlier model predictions. Without this information, every retraining cycle risks absorbing distortions created by the model’s own prior use. In one documented clinical example, a retrained model performed worse even after receiving six times as much training data because AI-influenced labels had contaminated the dataset.
The second is a baseline measure of clinician performance gathered in AI-off conditions before deployment. This is the only reliable way to understand what the Clinician Learning Loop is doing over time. Without a pre-deployment baseline, there is no meaningful reference point for identifying trust miscalibration, deskilling, or never-skilling.
The third is adherence flags: structured records showing whether clinicians followed the model’s recommendations on an encounter-by-encounter basis. Without adherence tracking, retraining cannot separate outcomes that reflect the model’s true predictive performance from those that reflect clinicians’ responses to its recommendations.
Two additional elements complete the minimum viable dataset:
Clinician identifiers for longitudinal tracking, so behavioral drift can be seen at the individual level rather than only in aggregate.
Cumulative alert exposure per clinician, measured over a rolling 90-day window, so institutions can monitor the dose-response relationship between alert burden and behavioral degradation before the effects become permanent.
Right now, no post-deployment monitoring system brings all of this together in real time. That is the real issue. The field does not lack ambition. It lacks infrastructure.
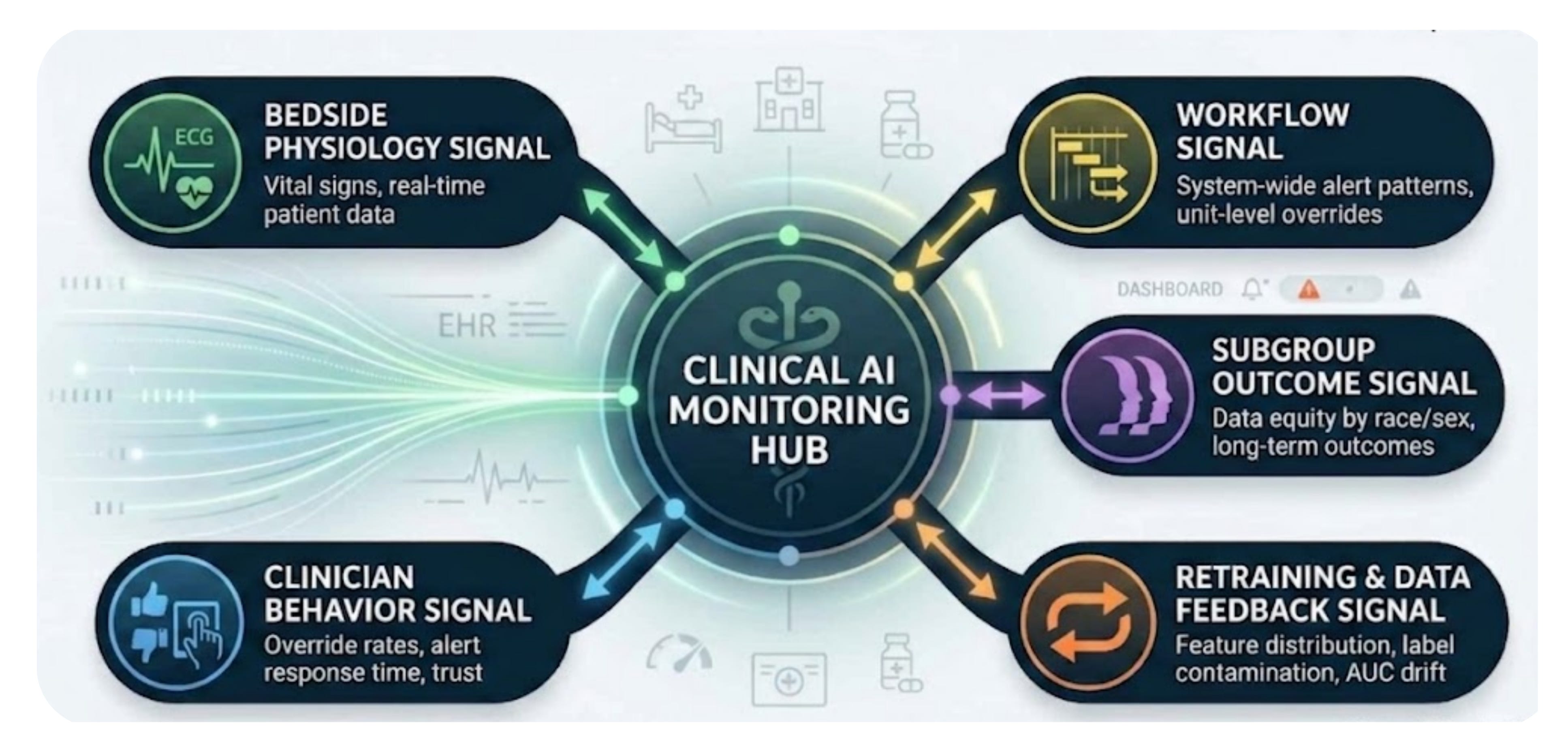
The Five Signal Types: What They Are, When They Appear, and Who Owns Them
To detect the three feedback loops, institutions need to distinguish among five distinct signal types that current systems often blur together. Each one appears at a different stage after deployment, depends on different infrastructure, and belongs to different stakeholders. Treating them as interchangeable is exactly how health systems end up with dashboards that seem comprehensive while missing the most important problems.
1. The Bedside Signal
The bedside signal reflects patient physiology directly — things like vital signs, clinical deterioration markers, and early warning scores. It is independent of the AI system and available in real time, making it useful for understanding what is happening with the patient in the moment.
But that is also its limitation. It tells you what is happening, not why. A worsening bedside signal cannot, on its own, implicate the algorithm. It only becomes meaningful during algorithmic surveillance when paired with the other four signal types.
Ownership: the clinical team.
2. The Clinician Behavior Signal
The clinician behavior signal captures how individual clinicians respond to AI recommendations over time. This includes override rates by clinician and alert type, time-to-decision after alert presentation, cumulative alert exposure over a rolling 90-day period, and agreement rates with AI recommendations. To make this signal useful, institutions need clinician-level longitudinal tracking rather than broad aggregate measures.
This signal commonly emerges within days to weeks of deployment, making it the earliest detectable indicator among the five. For example, a clinician whose override rate is climbing, whose decision-making is becoming faster, and whose alert exposure falls in the highest quartile may already be showing signs of automation bias before any patient outcome data are available.
Ownership: clinical informatics, with escalation to the department chief and the AI governance committee.
3. The Workflow Signal
The workflow signal reflects aggregate system performance. It includes unit-level override rates, unusual alert-firing patterns, irregularities in system response times, and the share of overrides submitted without a structured reason. It looks across clinicians and encounters to identify system-wide patterns rather than individual decisions.
Most health systems already collect the raw data needed for this signal through EHR audit logs. What they usually lack is the analytical capability to monitor those logs for meaningful anomalies.
Ownership: IT and informatics, with escalation to quality and safety leadership as well as operations.
4. The Subgroup Outcome Signal
The subgroup outcome signal tracks how algorithm performance differs across patient populations — by race, ethnicity, age, sex, comorbidity burden, and combinations of those factors. It is the most important signal for health equity, but also the slowest to appear, because it depends on outcome data that may take weeks or months to accumulate.
This is also the signal most likely to reveal endogenous bias amplification. Aggregate performance measures will not capture that. Only subgroup-level stratification will.
Ownership: quality and safety, with escalation to the AI governance committee and executive leadership.
5. The Retraining and Data Feedback Signal
The retraining and data feedback signal monitors how model inputs, outputs, and training data evolve over the course of deployment. It requires model-specific instrumentation, including feature distribution tracking with rolling windows, label contamination monitoring, adherence-weighted performance estimates, and AUROC tracking against pre-deployment benchmarks.
This is the signal that most directly detects the Training Feedback Loop. An AUROC drop of more than 0.05 from baseline should trigger investigation. A 9% to 39% decline in specificity after retraining is a quantified warning sign of feedback loop contamination.
Ownership: data science and ML operations, with escalation to both the governance committee and the vendor.
What This Means for Healthcare Institutions
If your institution has already deployed clinical AI, the real question is not whether the feedback loops described in Issue 03 exist.
The real question is whether you can see them.
Health executives and governance leaders should be asking:
Do we track override rates over time by clinician and alert type rather than only in aggregate?
Do we know if our retraining data has already been contaminated by prior model use?
Do we have a way to measure clinician performance without AI assistance?
Do we continuously monitor subgroup performance rather than only checking it at deployment?
Do we know which signals appear first and who is responsible for escalation when thresholds are crossed?
If the answer is no, then feedback loops may already be active in your institution without any meaningful surveillance signal in place.
That is not an individual failure. It is a field-wide blind spot that can no longer be defended as being invisible.
What Comes Next
Issue 03 introduced the mechanism—three feedback loops and the epistemological challenge they pose.
Issue 04 has now laid out the governance implications, the infrastructure requirements, and the five signal types that any real surveillance system must be able to distinguish.
Issue 05 will introduce the six-domain surveillance architecture, the operational framework that enables surveillance, detection, and mitigation at an institutional scale. These domains are not abstract ideas. They are the practical answer to the central question this issue raises: if feedback loops are inevitable, what does a health system actually need to build in order to see them?
Drift cannot be prevented. But it can be detected. And detection is where the discipline begins.
Subscribe to get each new issue of The Epidemiology of Algorithms delivered to your email inbox.
“Trust in algorithmic systems should be continuously earned through rigorous, population-level surveillance rather than historically inherited from initial validation or deployment approval.” — Anne E. Burnley, MD, MHS, MS