
Issue 03 - The System Talks Back: Feedback Loops and the Epistemology of Drift
Anne E. Burnley, MD, MHS, MS | The Epidemiology of Algorithms | Issue 03
In Issue 02, I introduced the Algorithm Exposure Model: a causal chain for understanding how clinical AI produces effects not one patient at a time, but across entire populations simultaneously.
That model was deliberately linear.
It began with the algorithm as agent, moved through algorithm output, clinician interpretation, clinical decision, patient, and patient outcome, and showed how the clinical environment modifies every step.
That structure was necessary.
It clarified the architecture of exposure.
But it was also incomplete.
A causal chain is useful because it imposes order. Inputs move toward outputs. Causes precede effects. The model acts, and the world responds.
Deployed clinical AI does not remain that kind of system for long.
Once it enters a real clinical environment, it does not simply generate outputs and wait passively for the world to react. Clinicians adapt to it. Institutions reorganize around it. And in some systems, decisions made in response to the model become part of the data used later to evaluate or retrain the next version.
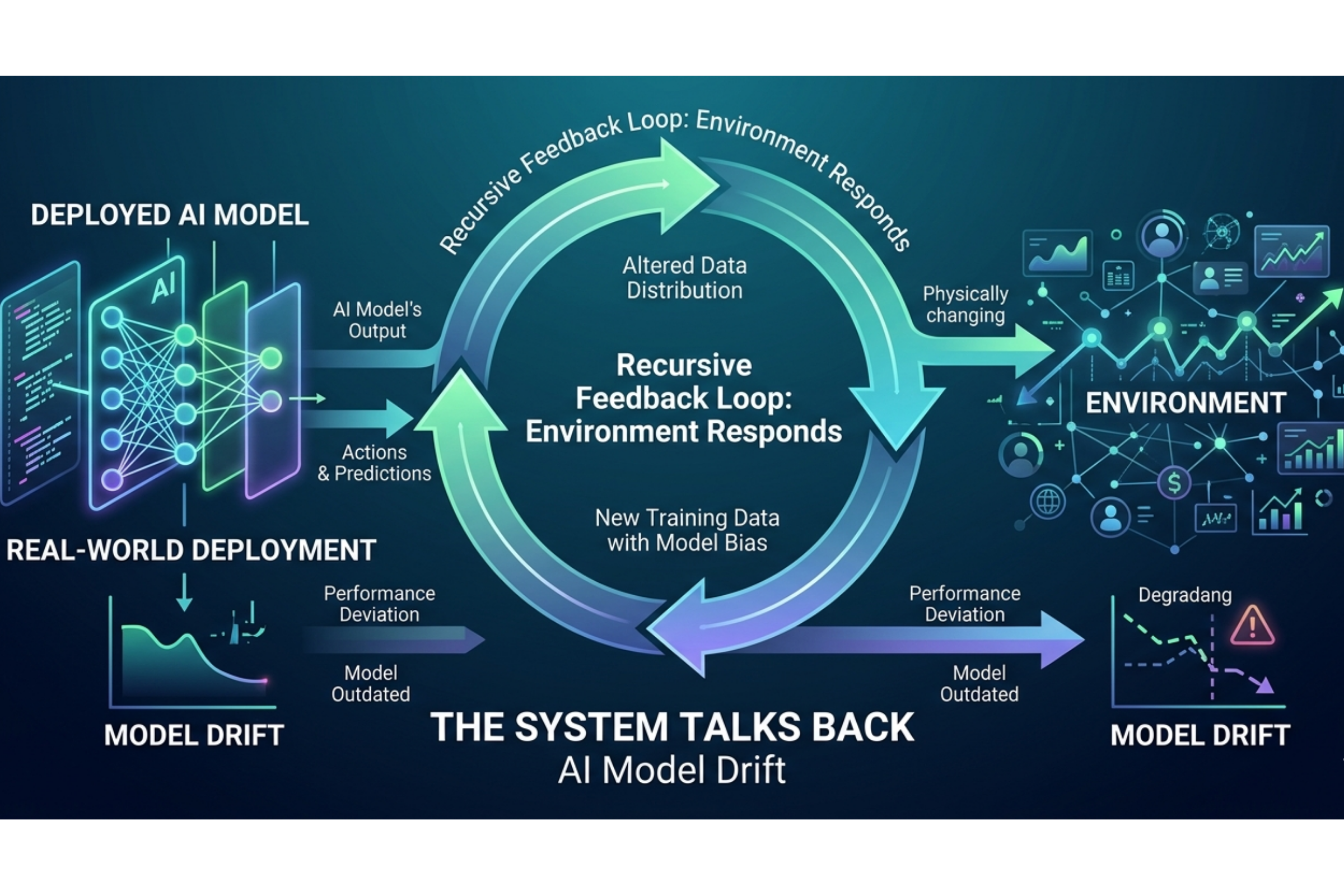
The output begins to shape the input. The effect begins to modify the cause. That is what Figure 2 adds.
Figure 1 showed us the architecture of exposure. Figure 2 adds motion.
From causal chain to living system
The six nodes of the Algorithm Exposure Model are unchanged. The clinical environment continues to function as an effect modifier across all nodes and transitions.
What is new are three recursive arcs: feedback loops that connect downstream effects back to upstream system behavior.
Those loops turn a linear causal model into a living system.
And that distinction matters, because the problem is not only that clinical AI has downstream effects.
It is those effects that can return to the system, reshape its future behavior, and make the resulting harms harder to detect.
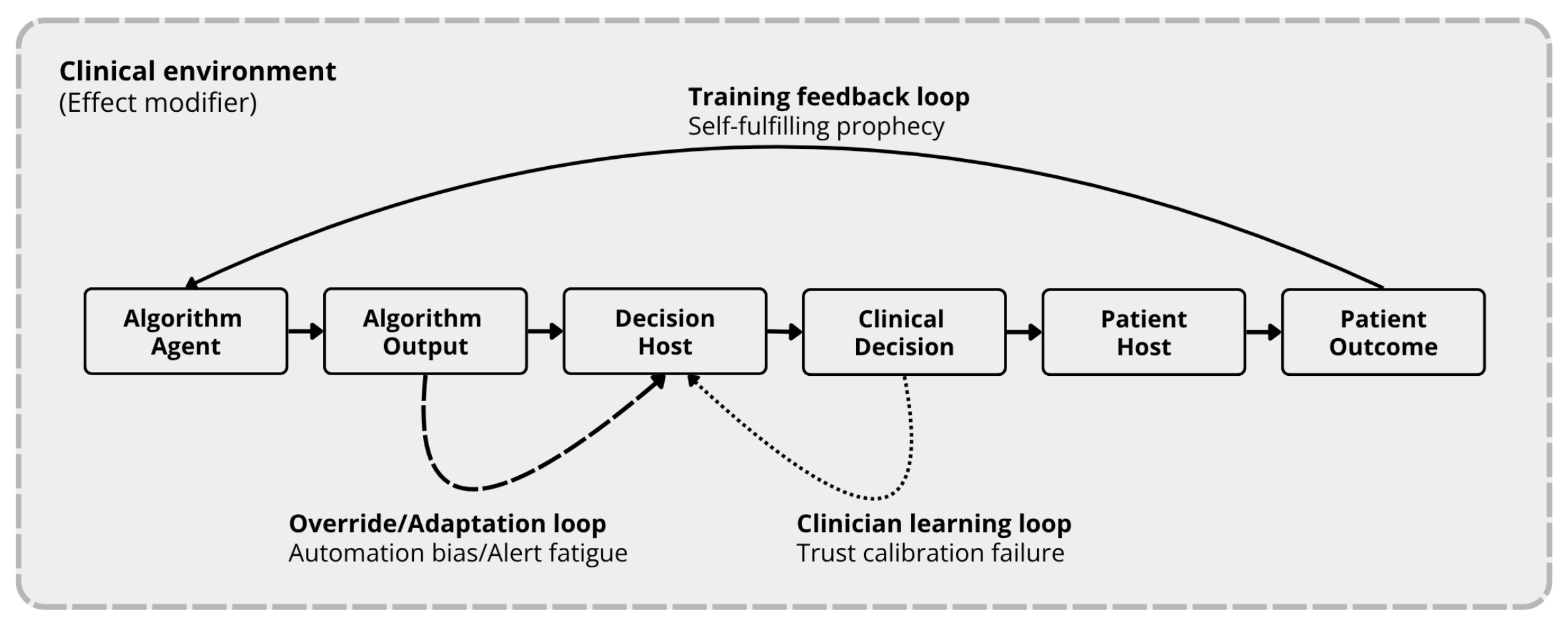
Figure 2. The Algorithm Exposure Model with Feedback Loops. Three recursive arcs connect downstream effects back to upstream system behavior, turning the linear causal chain from Figure 1 into a living system. The clinical environment functions as an effect modifier across all nodes and transitions.
The three loops are:
The Override/Adaptation Loop — from decision host back to algorithm output
The Clinician Learning Loop — from clinical decision back to decision host
The Training Feedback Loop — from patient outcome back to algorithm agent
Each has a distinct mechanism. Each has a distinct failure mode. And each operates in ways that are difficult to see in a single patient encounter.
That is the point.
The Override/Adaptation Loop: where automation bias lives
The most recognizable loop is the shortest one.
The Override/Adaptation Loop sits between the clinician node and the algorithm output node. Every time a clinician receives an alert, recommendation, score, or classification, they must decide whether to accept, modify, or override it.
That decision is never purely technical.
It is shaped by trust, fatigue, workload, recent experience with the system, alert burden, and the cognitive cost of checking whether the recommendation is correct.
Over time, what matters is not any single decision. It is the pattern of those decisions across hundreds or thousands of encounters.
This is where automation bias lives.
The evidence base here is already substantial. Across specialties, AI recommendations can influence clinical decision-making powerfully — sometimes appropriately, sometimes not. Experience may moderate that effect, but it does not eliminate it. Even highly experienced clinicians remain vulnerable when an output appears plausible enough, and the burden of verification is high.
Alert volume compounds the problem.
As exposure increases, adherence patterns degrade. What begins as decision support becomes background noise. The system continues to generate outputs. The clinician continues to adapt. And the aggregate pattern that emerges becomes the institution’s operational reality, regardless of what the original validation study claimed.
This loop often generates one of the earliest detectable signals in a deployed system. Changes in override rates, response rates, and alert fatigue can appear within days to weeks of deployment — long before a health system has enough outcome data to say anything definitive about patient harm.
That makes this loop the first place a surveillance architecture should look.
The Clinician Learning Loop: trust miscalibration over time
The second loop is slower and less visible.
The Clinician Learning Loop runs from the clinical decision node back to the clinician node. It reflects the fact that clinicians do not merely use AI systems.
They learn from them.
They update their internal model of the system’s reliability, when to trust it, and when to ignore it.
Sometimes that learning is appropriate. Sometimes it is not.
The problem is not simply overtrust or undertrust in the abstract. Repeated exposure to algorithmic output can reshape clinical reasoning itself. Trust can become miscalibrated either gradually over months of use or rapidly after brief exposure to outputs that appear consistently correct.
That miscalibration has a name in the literature — actually, three names: Deskilling, never-skilling, and mis-skilling.
Deskilling is the loss of previously acquired clinical ability through disuse.
Never-skilling is the failure to develop competency because the system scaffolds the task before the clinician can internalize it.
Mis-skilling is the reinforcement of incorrect behavior when algorithmic error becomes part of the clinician’s own reasoning pattern.
All three reduce the clinician’s ability to detect error independently, and that matters because, in the Algorithm Exposure Model, the clinician is not a passive recipient of output. The clinician is the decision host.
If the decision host is being reshaped by the system, then the system’s future behavior is being altered indirectly through the human-in-the-loop, meant to regulate it.
The clinician learning loop is also the least well-instrumented. Most health systems do not measure trust calibration in real time. They do not track independent baseline performance in AI-off conditions. They also do not routinely test agreement rates against challenge cases designed to reveal overreliance.
Without those measures, trust miscalibration remains not only unmanaged but largely unseen.
The Training Feedback Loop: the self-fulfilling system
The longest and most concerning loop runs from the patient outcome node back to the algorithm agent node itself. This is concerning because this is the loop in which clinical AI begins to learn from its own effects.
If algorithmic predictions influence clinical decisions, and those decisions influence outcomes, and those outcomes later enter the data used for evaluation or retraining, then the model is no longer learning from an independent world. It is learning from a world it has already helped shape.
That is a fundamentally different problem from simple model degradation over time. It is a self-fulfilling system.
Recent literature has begun to name this directly. In ICU prognostic models, researchers have described model-mediated intervention as a mechanism that changes the relationship between predictors and outcomes after deployment. In resuscitation science, self-fulfilling prophecies arise when treatment decisions are not adequately represented in training, when human-machine interaction compounds those decisions, and when historically sensible clinical choices become structurally misleading as medicine advances.
Simulation work has made the stakes concrete. Models retrained after deployment can lose substantial specificity precisely because the data no longer mean what they meant before deployment. A model that appears to be improving by incorporating more recent data may be introducing distortions from its prior use. In one documented clinical case, a retrained model performed worse despite having six times as much training data because AI-influenced labels had contaminated the training set.
This loop is not only hard to detect, but it also changes the meaning of the evidence used to detect it.
More data may not correct the model, in some cases, more data makes it worse.
The epistemology of drift
This is where the argument moves from mechanism to interpretation.
Standard drift literature often considers performance degradation as external to the model. The patient population evolves. Disease prevalence varies. Clinical protocols are updated. The environment changes. The model must adapt accordingly.
That framing is not only wrong but also incomplete.
The feedback loops in Figure 2 introduce a different category: endogenous drift.
This is not drift happening to the model from outside; it is drift the model helps create by its own deployment.
Endogenous drift emerges when algorithmic output alters clinician behavior, workflow patterns, data provenance, and the relationship between predictors and outcomes.
That distinction matters because it changes what can be known about error:
· A model that improves outcomes may appear to degrade because it has changed the world it was trained to predict.
· A model that appears to perform well may do so only because its outputs have shaped the outcomes now being counted as ground truth.
· A system may seem stable in the aggregate while subgroup harm quietly intensifies beneath the surface.
The loops do not merely produce errors; they also obscure them:
· A self-fulfilling prophecy can look like a successful prediction.
· Alert fatigue can look like clinician noncompliance.
· Trust miscalibration can look like individual variation.
· Retraining contamination can look like model adaptation.
That is the epistemic problem.
The system can alter the conditions under which it is observed, and in doing so, make its own failures harder to see.
The loops are not independent
These feedback loops do not operate independently.
The Override/Adaptation Loop can alter the data-generating process for the Training Feedback Loop. The Clinician Learning Loop can reduce the clinician’s ability to detect errors, allowing flawed outputs to pass uncorrected into future data. Behavioral shifts become retraining distortions. Retraining distortions make outputs less reliable. Less reliable outputs further degrade trust calibration.
This is how harm compounds.
Not usually as a single dramatic failure, but as a gradually tightening cycle.
A system that generates automation bias produces override patterns that contaminate training data; likewise, contaminated training data creates a model with more systematic error. More systematic error deepens trust miscalibration. More miscalibration reduces error detection. Reduced error detection allows the next round of labels and outcomes to carry the distortion forward.
The loops tighten around one another.
That is why this is not a series of isolated problems. It is a system problem.
At the bedside, none of these patterns are obvious; however, as they aggregate at the population level over time, they become detectable.
The reason why incident review cannot solve this problem
Individual incident reviews cannot solve this problem because they were never designed to do so.
Incident review works best when harm is discrete, visible, and attributable to a bounded event. Feedback-loop harms are different. They unfold gradually, distribute across populations, and can alter the evidentiary frame through which later events are interpreted.
In other words, the problem is not simply that we are missing isolated failures. We are using methods built for isolated failures to monitor recursive systems. That mismatch guarantees blind spots.
A surveillance architecture for deployed clinical AI must be able to detect early behavioral adaptation, monitor evolving trust calibration, and interrogate whether retraining data remain epistemically meaningful after deployment.
Without that infrastructure, health systems may continue to rely on approval, validation, or aggregate performance summaries long after those measures no longer reflect the true state of the system.
The governance problem after deployment
Clinical AI should not be understood as a tool acting on a static environment.
Once deployed, it enters into relationships with clinicians, institutions, workflows, and data systems that change in response to it.
Those responses loop back.
They affect future decisions, future measurements, and future models.
That is why trust in algorithmic systems cannot be permanently inherited from initial validation or deployment approval. It has to be continuously earned through rigorous, population-level surveillance capable of seeing the recursive dynamics that ordinary monitoring misses.
The key question is no longer just whether a model was valid when deployed. It is whether the system it evolves into after deployment remains understandable enough to govern safely.
“Trust in algorithmic systems should be continuously earned through rigorous, population-level surveillance rather than historically inherited from initial validation or deployment approval.”
What comes next:
Issue 03 identifies the problem. In issue 04, we will examine what it would take to monitor these loops in practice.